


Four-Room¶
Action Space |
Discrete(4) |
Observation Shape |
(14,) |
Observation High |
[13 13 13 13 13 13 13 13 13 13 13 13 13 13] |
Observation Low |
[0 0 0 0 0 0 0 0 0 0 0 0 0 0] |
Reward Shape |
(3,) |
Reward High |
[1. 1. 1.] |
Reward Low |
[0. 0. 0.] |
Import |
|
Description¶
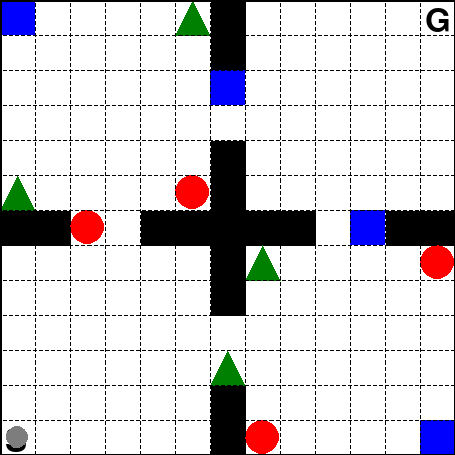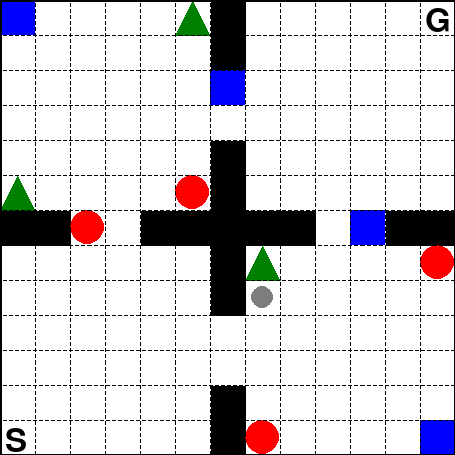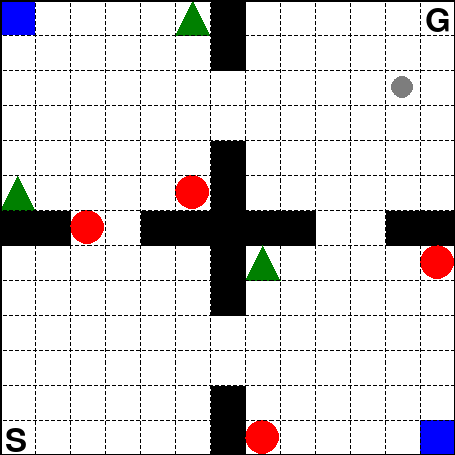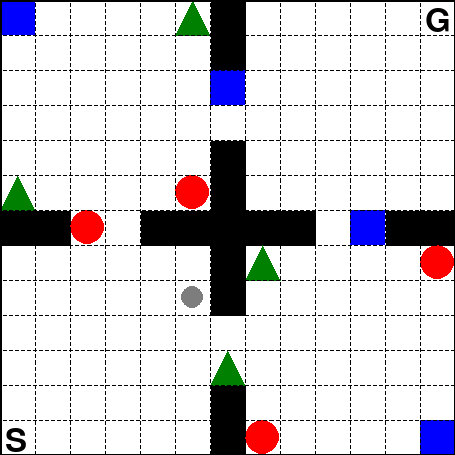
A discretized version of the gridworld environment introduced in [1]. Here, an agent learns to collect shapes with positive reward, while avoid those with negative reward, and then travel to a fixed goal. The gridworld is split into four rooms separated by walls with passage-ways.
References¶
[1] Barreto, André, et al. “Successor Features for Transfer in Reinforcement Learning.” NIPS. 2017.
Observation Space¶
The observation contains the 2D position of the agent in the gridworld, plus a binary vector indicating which items were collected.
Action Space¶
The action space is discrete with 4 actions: left, up, right, down.
Reward Space¶
The reward is a 3-dimensional vector with the following components:
+1 if collected a blue square, else 0
+1 if collected a green triangle, else 0
+1 if collected a red circle, else 0
Starting State¶
The agent starts in the lower left of the map.
Episode Termination¶
The episode terminates when the agent reaches the goal state, G.
Arguments¶
maze: Array containing the gridworld map. See MAZE for an example.
Credits¶
Code adapted from: Mike Gimelfarb’s source.